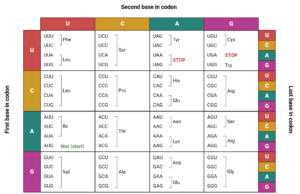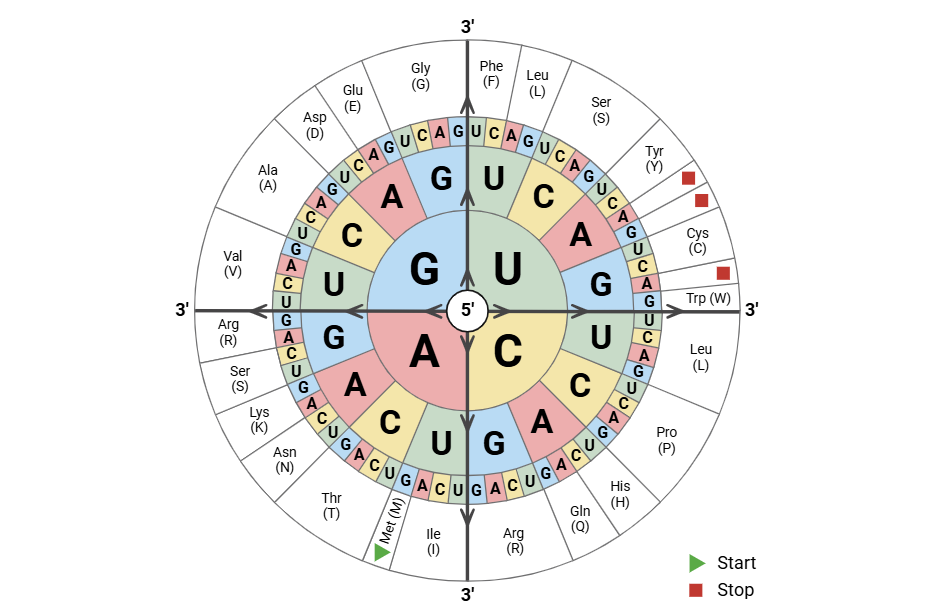
Imagine trying to communicate with someone who speaks the same language but uses a different dialect. You both understand the words, but some phrases might sound awkward, or certain terms are preferred over others. This is precisely what happens at the molecular level with Codon Usage Bias (CUB).
While the genetic code is nearly universal, meaning a specific three-letter DNA “word” (codon) generally codes for the same amino acid in all life forms, organisms don’t use these “words” with equal frequency. Some codons are heavily preferred, while others are rarely seen, even when they code for the exact same amino acid. This isn’t just a quirk of nature; it’s a profound layer of biological regulation with immense implications for biotechnology, medicine, and our understanding of evolution.
What is Codon Usage Bias? The Dialect of Life
The genetic code is degenerate, meaning most amino acids are specified by more than one codon. For example, the amino acid Leucine can be encoded by six different codons: UUA, UUG, CUU, CUC, CUA, and CUG.
Codon Usage Bias (CUB) is the phenomenon where, among these synonymous codons (codons that code for the same amino acid), one or more are used significantly more often than others within a particular organism’s genome. This preference is not random; it’s a finely tuned evolutionary adaptation.

Analogy: The Molecular Dialect
- Language: The genetic code (DNA/RNA sequences).
- Words: Codons (e.g., CUG, UUG).
- Meaning: Amino acids (e.g., Leucine).
- Organism: A speaker of the language.
- Dialect: The specific preferences for synonymous codons (CUB).
Read More: Codon Chart and Codon Wheel – Explained
Why Does it Happen? The Evolutionary Tug-of-War
Codon Usage Bias isn’t arbitrary; it arises from a dynamic interplay of evolutionary forces, primarily mutation and selection.
Translational Selection: The Need for Speed and Accuracy
This is considered the primary driver of CUB, especially for highly expressed genes.

- tRNA Abundance: The cell contains different types of transfer RNA (tRNA) molecules, each responsible for carrying a specific amino acid and recognizing its corresponding codon. Some tRNAs are much more abundant than others.
- The Match: Organisms tend to prefer codons that have a cognate tRNA (a matching tRNA) that is also highly abundant.
- Efficiency: When a ribosome encounters a frequently used codon, there’s a high chance that the matching abundant tRNA is readily available. This allows for faster and more accurate protein synthesis.
- Protein Folding: Rapid translation is crucial for proteins that need to be made in large quantities. However, sometimes a slight pause (caused by a rare codon) can be beneficial, allowing parts of the nascent protein to fold correctly before the next section emerges from the ribosome. This creates a delicate balance between speed and proper function.
Mutational Bias: The Genetic Drift
The fundamental machinery that copies and repairs DNA is not perfectly unbiased.
- GC Content: Some organisms have a natural bias towards DNA sequences rich in Guanine (G) and Cytosine (C), while others prefer Adenine (A) and Thymine (T). This mutational bias can influence the composition of codons throughout the genome. For example, in a GC-rich organism, codons ending in G or C might become more prevalent simply due to the higher availability of those nucleotides during replication.
- Randomness: Over long evolutionary periods, especially in genes under weak selective pressure, random mutations can lead to the fixation of certain synonymous codons purely by chance (genetic drift), contributing to the overall bias.
Read More: Chi-square Test – Formula and Applications
How Do We Measure Codon Bias? Decoding the Dialect?
A. Relative Synonymous Codon Usage (RSCU)
RSCU is a simple and intuitive measure that tells you how often a specific codon is used compared to what would be expected if all synonymous codons for that amino acid were used equally.
- Calculation: For each amino acid, divide the observed frequency of a specific codon by the expected frequency (which is 1 divided by the number of synonymous codons for that amino acid).
- Interpretation:
- RSCU = 1: The codon is used with the expected frequency (no bias).
- RSCU > 1: The codon is preferred (used more often than expected).
- RSCU < 1: The codon is underrepresented (used less often than expected).
Example: Leucine (6 synonymous codons) If CUG it appears 60 times in a gene, and the other 5 Leucine codons appear 10 times each: Total Leucine codons = 60 + (5 * 10) = 110. Expected frequency for CUG = 110 / 6 = 18.33 RSCU for CUG = 60 / 18.33 = 3.27 (Highly preferred)
B. Codon Adaptation Index (CAI)
CAI is a powerful measure that quantifies how “adapted” a gene’s codon usage is to the translational machinery of a specific organism. It’s particularly useful for predicting gene expression levels.
- Calculation: It compares the codon usage of a gene to a “reference set” of highly expressed genes (e.g., ribosomal protein genes) from the target organism. These highly expressed genes are assumed to use the “optimal” codons.
- Interpretation:
- CAI = 1: The gene uses only the optimal codons, matching the reference set perfectly.
- CAI = 0: The gene uses only the rarest codons.
- Higher CAI: Generally correlates with higher mRNA translational efficiency and protein expression. A good CAI is typically 0.80 – 0.95.
C. Effective Number of Codons (ENC)
ENC measures the diversity of codon usage within a gene, regardless of a reference set. It indicates how biased the codon usage is, ranging from extreme bias (only one codon per amino acid) to no bias (all synonymous codons used equally).
- Interpretation:
- ENC = 20: Extreme bias (only 20 unique codons used, one for each amino acid).
- ENC = 61: No bias (all 61 sense codons used equally).
- Lower ENC: Indicates stronger codon usage bias.
Read More: Understanding P-Value Tables | Z-Table, T-Table, Chi-square Table, and F-Table
The Power of Codon Optimization: Rewriting for Success
The most significant practical application of codon usage bias is codon optimization in biotechnology. This involves modifying the DNA sequence of a gene to match the preferred codon usage of a host organism, without changing the amino acid sequence of the resulting protein.
Why Optimize? The Benefits
- Maximize Protein Expression: This is the primary reason. By using codons that are abundant in the host’s tRNA pool, you prevent the ribosome from stalling and ensure rapid, efficient protein synthesis, leading to significantly higher yields (often 10x-100x increase).
- Improve Translational Accuracy: Using preferred codons can reduce misincorporation of amino acids, leading to a higher proportion of correctly folded, functional protein.
- Enhance mRNA Stability: Codon choice can influence the secondary structure and stability of messenger RNA (mRNA). Optimized sequences often create more stable mRNAs, which persist longer in the cell, leading to more protein production.
- Avoid Harmful Elements: Optimization algorithms can remove unwanted DNA sequences (e.g., cryptic splice sites, premature polyadenylation signals in eukaryotes, or restriction enzyme recognition sites) without altering the protein.
- Simplify Gene Synthesis: Designing a gene with balanced GC content and avoiding repetitive sequences makes the actual chemical synthesis of the DNA much easier and cheaper.
Real-World Applications
Vaccine Development: A prime example is the mRNA COVID-19 vaccines. These vaccines deliver mRNA encoding viral proteins to human cells. To ensure high production of the viral antigen, the mRNA sequences are heavily codon-optimized for human codon usage, leading to robust immune responses.
Biopharmaceutical Production: From insulin to therapeutic antibodies, many biopharmaceuticals are produced in bacteria or yeast. Codon optimization is critical to achieve economically viable yields.
The Process of Optimization
- Input: Start with the amino acid sequence of your protein.
- Target Host Selection: Specify the organism in which you want to express the protein (e.g., E. coli K12, Homo sapiens, Saccharomyces cerevisiae).
- Algorithm Application: Specialized software analyzes the amino acid sequence and replaces each amino acid’s codons with the most preferred (or a balanced set of preferred) codons for the chosen host.
- Additional Checks: The software also checks and modifies the sequence to:
- Adjust GC content (typically aiming for 40-60%).
- Remove potential internal ribosome binding sites (in bacteria) or cryptic splice sites (in eukaryotes).
- Eliminate repetitive sequences or regions that could form strong mRNA secondary structures.
- Output: A new DNA sequence (synthesized commercially) that codes for the identical protein but is “translated” more efficiently by the host.
Beyond Simple Optimization: Nuances and Challenges
While often beneficial, codon optimization isn’t always a magic bullet, and sometimes a more nuanced approach is needed.
A. “De-optimization”
In some cases, researchers might intentionally use rare codons to reduce protein expression or to slow down translation at specific points, allowing the protein more time to fold correctly or to prevent aggregation. This is known as codon de-optimization. It’s used in areas like vaccine attenuation (weakening a virus by slowing its protein production).+1
B. Context-Dependent Effects
The “optimal” codon is not always static. The surrounding codons, the secondary structure of the mRNA, and even the growth conditions of the host cell can influence translation efficiency in complex ways that simple CAI scores might not capture.
C. Ribosome Trafficking
Codon usage can also influence how ribosomes move along the mRNA, affecting not just the speed of translation but also the interaction of the nascent polypeptide chain with chaperones and the endoplasmic reticulum (in eukaryotes).
Conclusion: The Hidden Language of Life
Codon usage bias, initially seen as a curious statistical observation, has evolved into a fundamental concept at the heart of molecular biology and a powerful tool in biotechnology. By understanding and manipulating the “dialect” of the genetic code, scientists can unlock the full potential of gene expression, leading to breakthroughs in medicine, industry, and our fundamental understanding of life itself. As synthetic biology continues to advance, the precise control offered by codon optimization will only become more critical in building the biological systems of the future.
Last Modified: